
www.cgranade.com/research/talks/quics/07-2016
Ferrie, Granade, Cory tfx
Granade et al. s87
Wiebe et al. tf3
Wiebe et al. 7nx
Wiebe et al. tdk
Granade, Combes, Cory bhdw
Wiebe and Granade bk9d
Liu and West 8c2
Doucet et al. bmch
Ferrie and Granade tdj
Granade 10012/9217
figure: Ferrie tb4
Svore et al. 1304.0741
Isard and Blake cc76f6
Rejection and Particle Filtering for Hamiltonian Learning
Cassandra E. Granade
Centre for Engineered Quantum Systems
$
\newcommand{\ee}{\mathrm{e}}
\newcommand{\ii}{\mathrm{i}}
\newcommand{\dd}{\mathrm{d}}
\newcommand{\id}{𝟙}
\newcommand{\TT}{\mathrm{T}}
\newcommand{\defeq}{\mathrel{:=}}
\newcommand{\Tr}{\operatorname{Tr}}
\newcommand{\Var}{\operatorname{Var}}
\newcommand{\Cov}{\operatorname{Cov}}
\newcommand{\rank}{\operatorname{rank}}
\newcommand{\expect}{\mathbb{E}}
\newcommand{\sket}[1]{|#1\rangle\negthinspace\rangle}
\newcommand{\sbraket}[1]{\langle\negthinspace\langle#1\rangle\negthinspace\rangle}
\newcommand{\Gini}{\operatorname{Ginibre}}
\newcommand{\supp}{\operatorname{supp}}
\newcommand{\ket}[1]{\left|#1\right\rangle}
\newcommand{\bra}[1]{\left\langle#1\right|}
\newcommand{\braket}[1]{\left\langle#1\right\rangle}
$
Learning Hamiltonians is critical to a range of QIP tasks:
- Metrology
- Learning magnetic fields, etc.
- Calibration
- Static field / pulse power / crosstalk, etc.
- Debugging/Diagnosis
- $T_2$ estimation, other noise finding
- Verification/Validation
- Analog and digital quantum simulation
To get there, we consider several different approaches to parameter estimation.
**Problem**: may be intractable to analytically compute $$ \hat{x} \defeq \int \Pr(\vec{x} | d; e) \dd\vec{x} = \int \frac{ \Pr(d | \vec{x}; e) }{ \int \Pr(d | \vec{x}; e) \Pr(\vec{x}) \dd\vec{x} } \Pr(\vec{x}) \dd\vec{x}. $$
Rejection Sampling Isn't Enough
Let $D = {d_1, \dots, d_k}$ be a set of data.
$$ \Pr(\text{accept} | \vec{x}) = \Pr(D | \vec{x}) = \prod_{d \in D} \Pr(d | \vec{x}) \overset{k \to \infty}{\longrightarrow} 0. $$
Example: Biased Coin $x = (p)$
$\Pr(H | p) = p$, $d \in \{H, T\}$.
$p \approx 0.5 \Longrightarrow \Pr(d_1, \dots, d_k | p) \approx 1 / 2^k$.
We will accept exponentially few samples!
Can compute $\bar{x}$, $\Sigma$ from one sample at a time by accumulating
$$ x_{\Sigma} = \sum x \text{ and } x^2_{\Sigma} = \sum x^2. $$
\begin{align} \bar{x} & = x_{\Sigma} / n_{\text{accept}} \\ \Sigma & = x^2_{\Sigma} / n_{\text{accept}} - \bar{x}^2. \end{align}
Welford's algorithm: numerically-stable modification.
Rejection Filtering (RejF)
Input: Prior mean $\bar{x}$, prior covariance $\Sigma$, number of attempts $m$.
- For each datum $d$ and experiment $e$:
- $n, \bar{x}', M_2 \gets 0$ Initialize Welford.
- While $n < m$:
- Draw $\vec{x} \sim \mathcal{N}(\bar{x}, \Sigma)$. Sample f/ prior.
- Accept $\vec{x}$ w/ $\Pr(d | \vec{x}; e)$.
- If accepted, update $n$, $\bar{x}'$, $M_2$.
- $\bar{x} \gets \bar{x}'$, $\Sigma \gets M_2 / (n - 1)$. Est. moments.
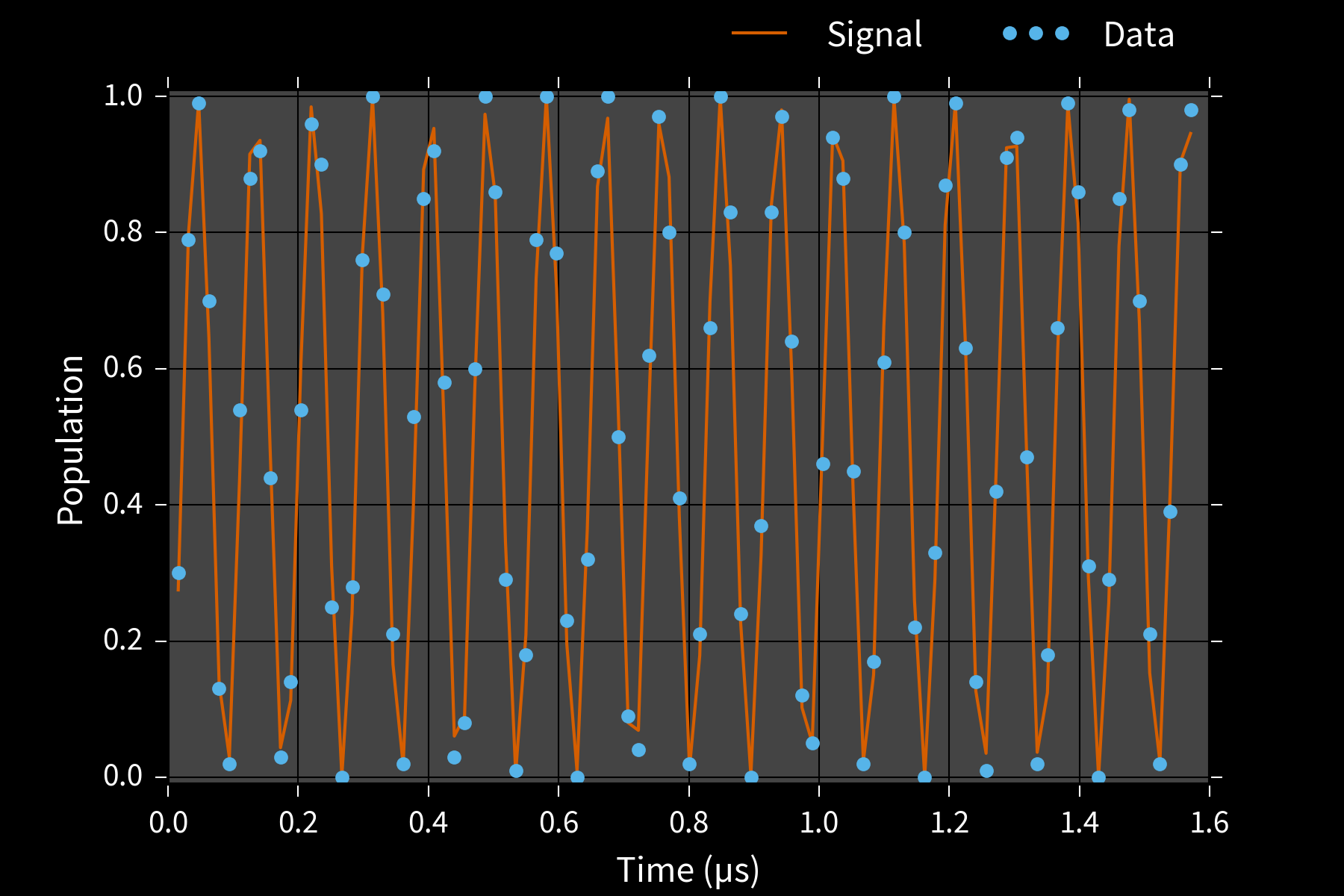
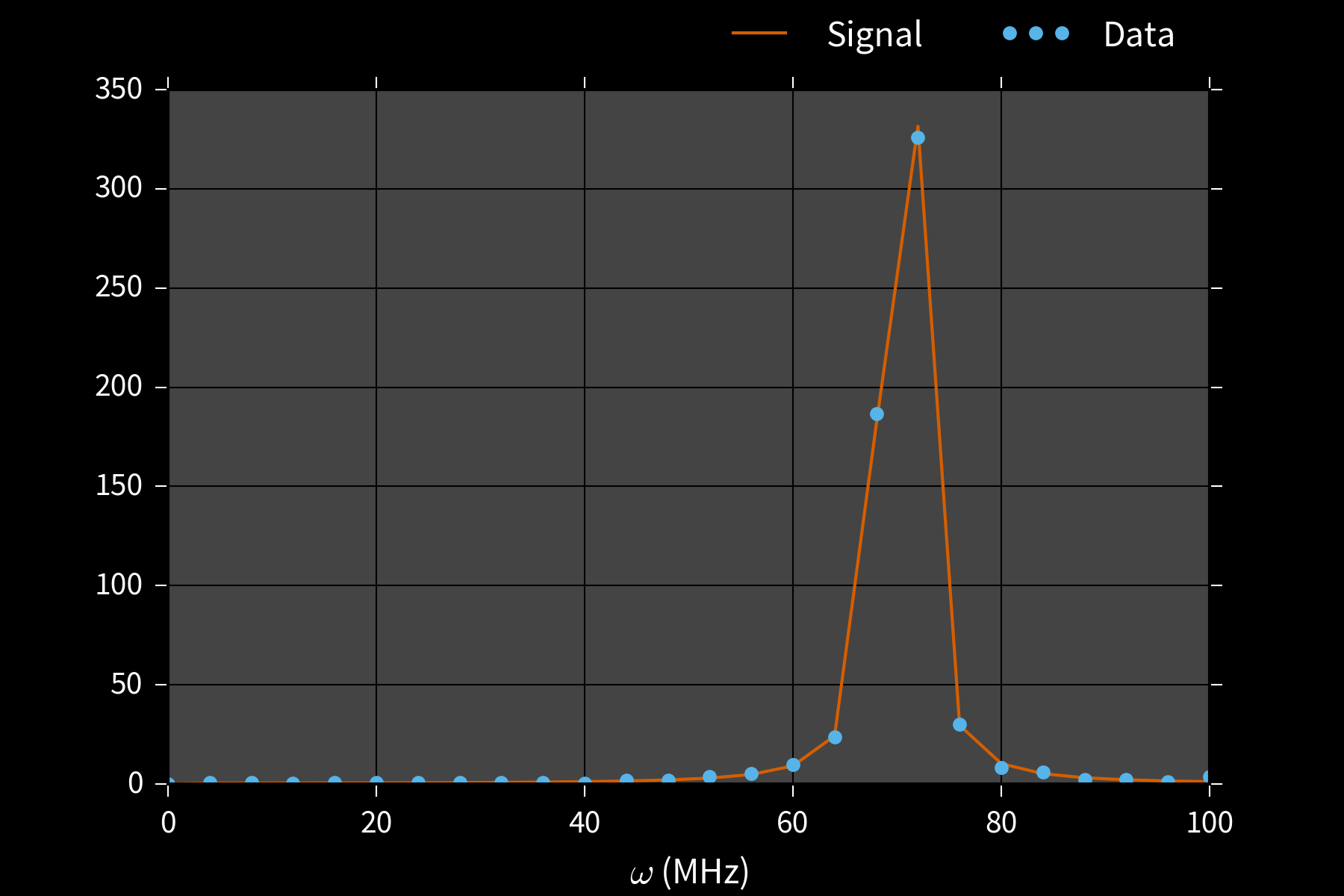
Example: Phase Estimation, $x = (\phi)$
Prepare state $\ket{\phi}$ s. t. $U\ket{\phi} = \ee^{\ii \phi}\ket{\phi}$, measure to learn $\phi$.
$\theta = 0 \Rightarrow$ freq. est likelihood, w/ $\phi = \omega$, $M = t$.
Applications
- Interferometry / metrology Higgins et al. crwd6w
- Gate calibration / robust PE Kimmel et al. bmrg
- Quantum simulation and chemistry Reiher et al. 1605.03590
Example: Phase Estimation, $x = (\phi)$
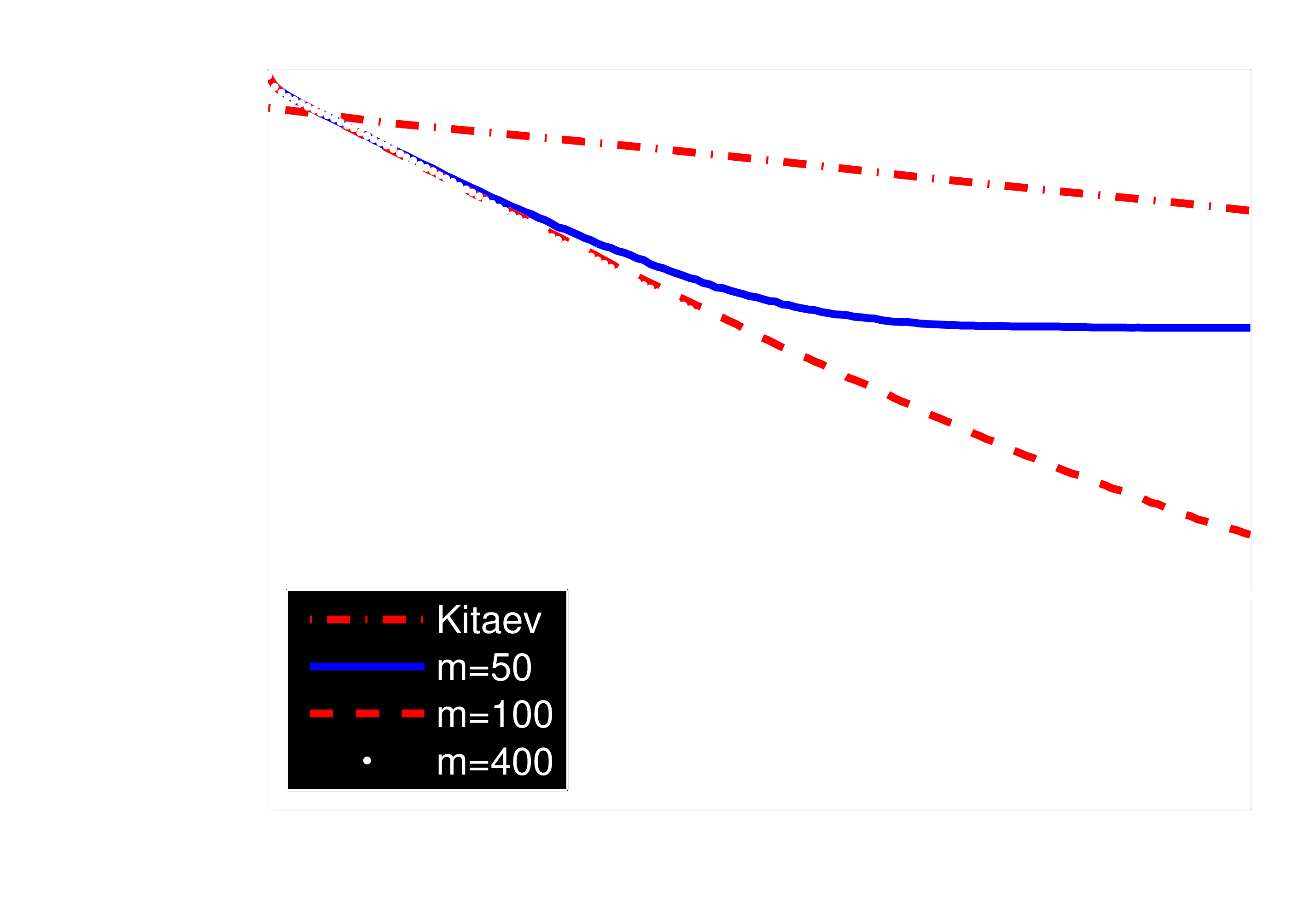
**Drawback**: RejF requires posterior after each datum to be $\approx$ Gaussian.
We can solve this by using a more general approach: - Weaken Gaussian assumption. - Generalize the rejection sampling step.
Liu-West Resampler
If we remember each sample $\vec{x}$, we can use them to relax RejF assumptions.
Input: $a, h \in [0, 1]$ s.t. $a^2 + h^2 = 1$, distribution $p(\vec{x})$.
- Approximate $\bar{x} \gets \expect[\vec{x}]$, $\Sigma \gets \operatorname{Cov}(\vec{x})$
- Draw parent $\vec{x}$ from $p(\vec{x})$.
- Draw $\vec{\epsilon} \sim \mathcal{N}(0, \Sigma)$.
- Return new sample $\vec{x}' \gets a \vec{x} + (1 - a) \bar{x} + h \vec{\epsilon}$.
Particles can represent distributions using either
weights or
positions.
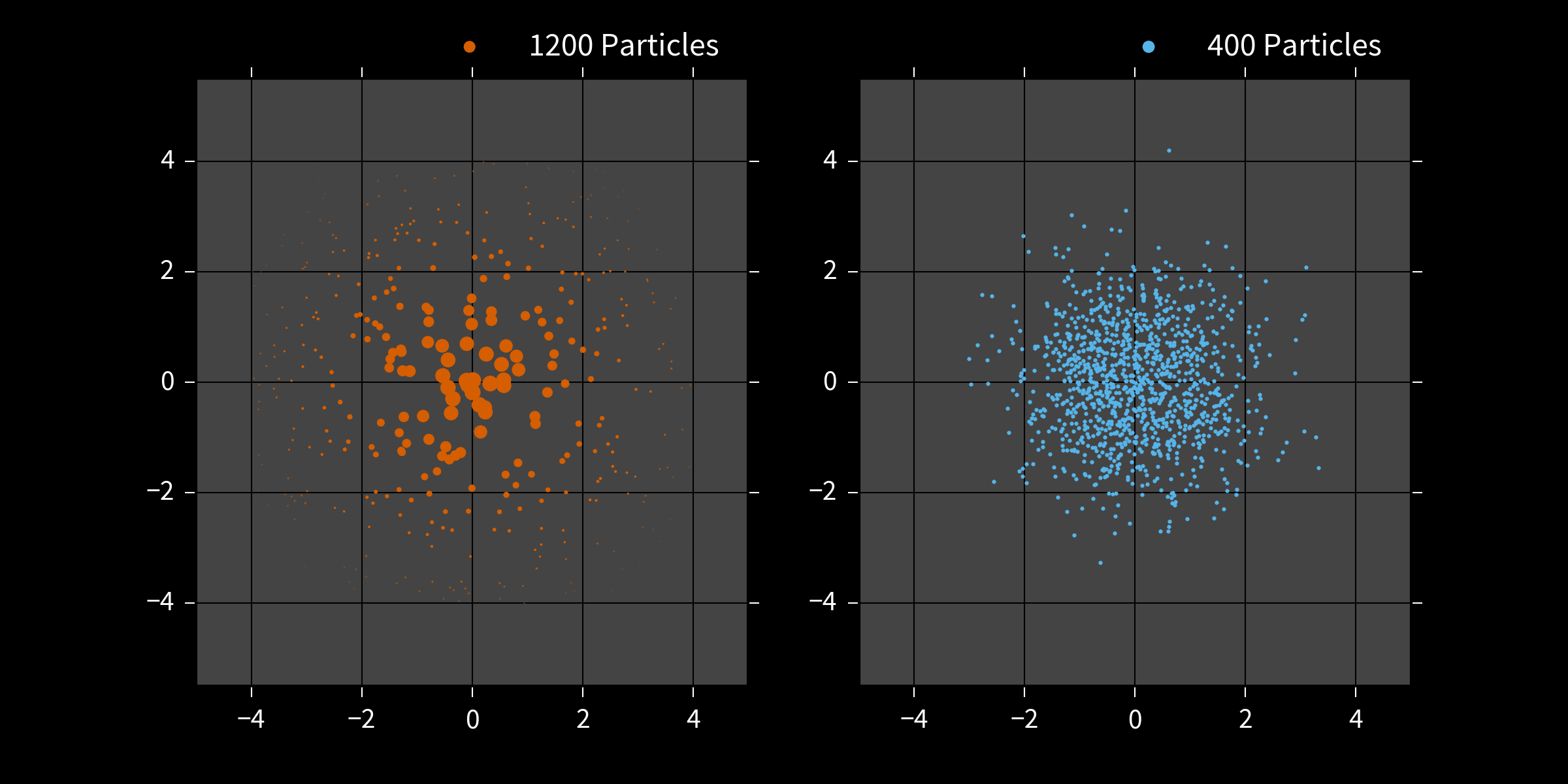
Particle Filter
- Draw $N$ initial samples $\vec{x}_i$ from the prior $\Pr(\vec{x})$ w/ uniform weights.
- Instead of rej. sampling, update weights by \begin{align} \tilde{w}_i & = w_i \times \Pr(d | \vec{x}_i; e) \end{align}
- Renormalize. \begin{align} w_i & \mapsto \tilde{w}_i / \sum_i \tilde{w}_i \end{align}
- Periodically use Liu-West to draw new $\{\vec{x}_i\}$ with uniform weights. Store posterior in positions.
Useful for Hamiltonian models...
...as well as other QIP tasks.
- Tomography
Huszár and Holsby
s86
Struchalin et al. bmg5
Ferrie 7nt
Granade et al. bhdw, 1605.05039 - Randomized benchmarking Granade et al. zmz
- Continuous measurement Chase and Geremia chk4q7
- Interferometry/metrology Granade 10012/9217
Example: $\vec{x} =$ COSY / Crosstalk
\( H(\omega_1, \omega_2, J) = \frac12 \left( \omega_1 \sigma_z \otimes \id + \omega_2 \id \otimes \sigma_z + J \sigma_z \otimes \sigma_z \right) \)
Example: $\vec{x} =$ COSY / Crosstalk
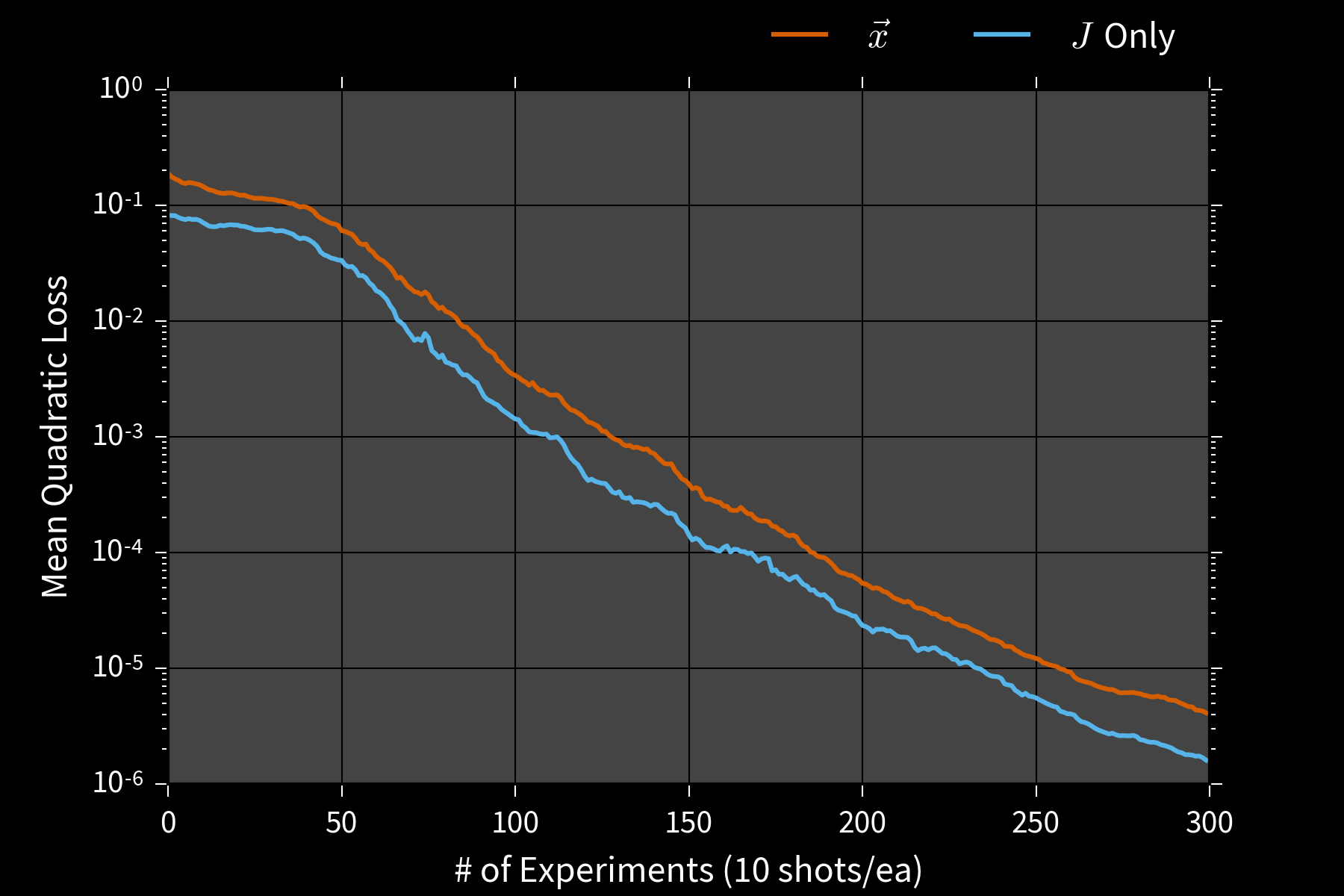
Error Bars
Particle filters also yield credible regions $X_\alpha$ s.t. $$ \Pr(\vec{x} \in X_\alpha | d; e) \ge \alpha. $$
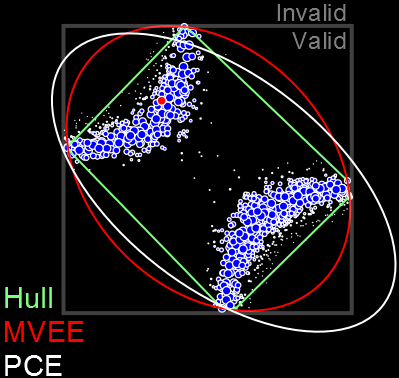
E.g.: Posterior covariance ellipse, convex hull, MVEE.
Assessing Performance
- Risk: average error given $\color{white}{\vec{x}}$
- Bayes risk: average error over $\color{white}{\vec{x}}$
Simulation Costs
\begin{align} \tilde{w}_i & = w_i \times \color{red}{\Pr(d | \vec{x}_i; e)} \\ w_i & \mapsto \tilde{w}_i / \sum_i \tilde{w}_i \end{align}
We design experiments using the
PGH: Particle Guess Heuristic
- Draw $\vec{x}_-, \vec{x}_-'$ from current posterior.
- Let $t = 1 / |\vec{x}_- - \vec{x}_-'|$.
- Return $e = (\vec{x}_-, t)$.
Adaptively chooses experiments such that
$t |\vec{x}_- - \vec{x}_-'| \approx\,$ constant.
One important approximation: physical locality.
Approximation quality can be bounded if Lieb-Robinson velocity is finite.
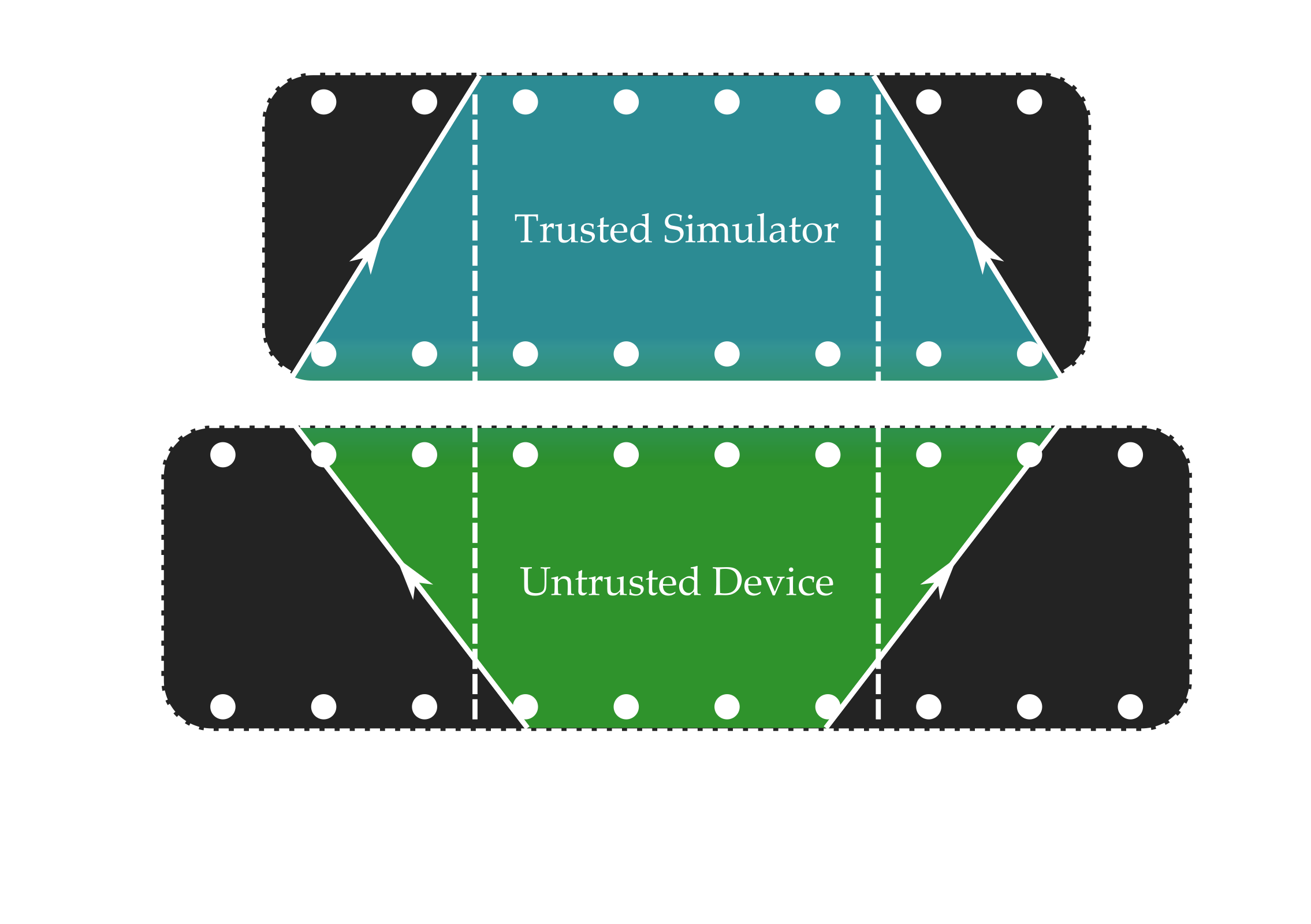
Scan trusted device across untrusted.
Run particle filter only on supported parameters.
50 qubit Ising chain, 8 qubit simulator, 4 qubit observable
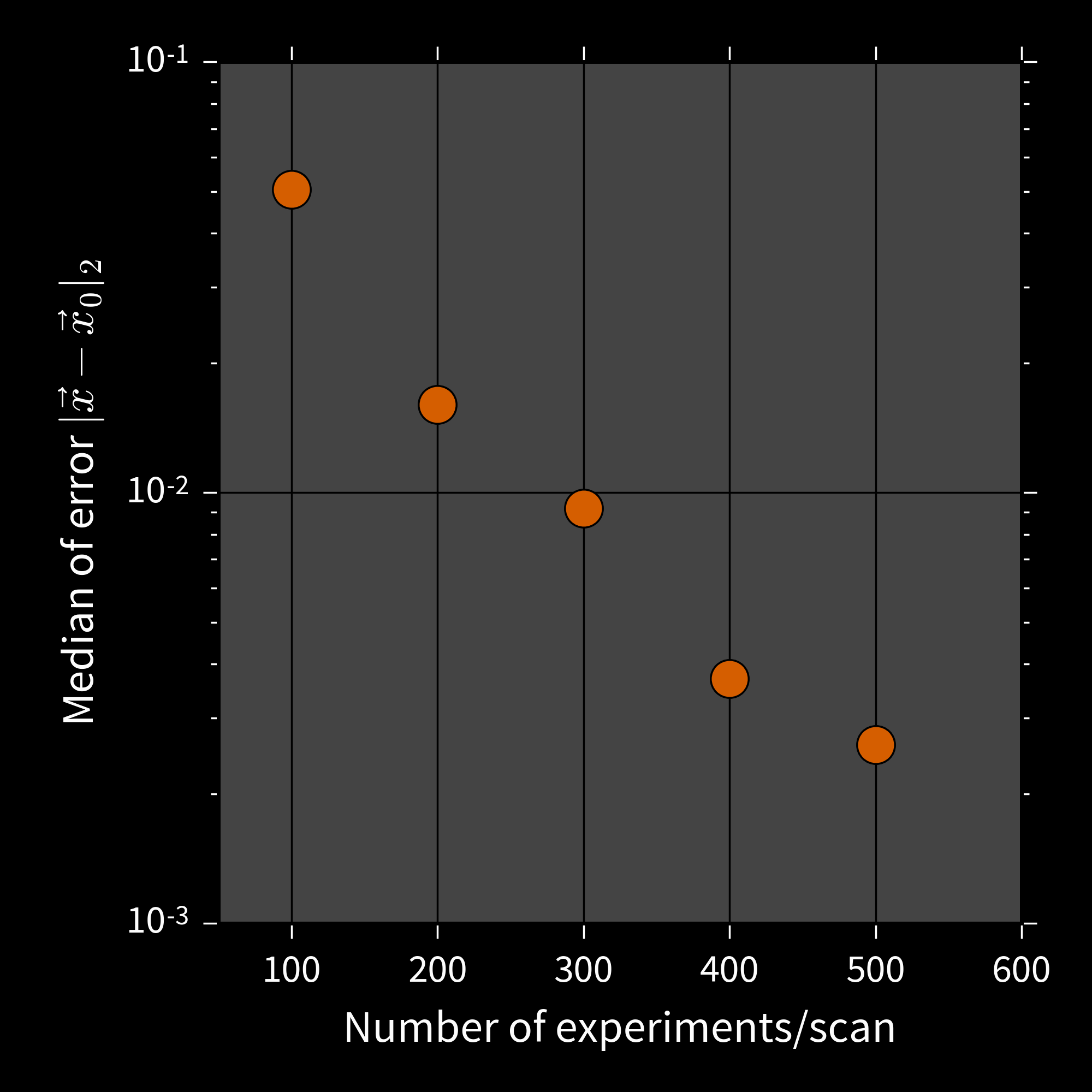
Going Further
- Hyperparameterization Granade et al. s87
-
$\Pr(d | y) = \expect_x[\Pr(d | x) \Pr(x | y)]$.
Allows composing w/ noise, inhomogeneity, etc. - Time-dependence Isard and Blake cc76f6
- Adding timestep update allows learning stochastic processes.
- Model selection Ferrie 7nt
- Using acceptance ratio or normalizations enables comparing models.
- Quantum filtering Wiebe and Granade 1512.03145
- Rejection filtering can be quantized using Harrow et al. bcz3hc.
Thank you!
Welford's Algorithm
Can compute $\bar{x}$, $\Sigma$ from one sample at a time. Numerically stable.
- $n, \bar{x}, M_2 \gets 0$.
- For each sample $x$:
- $n \gets n + 1$ Record # of samples
- $\Delta \gets x - \mu$ Diff to running mean
- $\bar{x} \gets \bar{x} + \Delta / n$ Update running mean
- $M_2 \gets M_2 + \Delta (x - \bar{x})$ Update running var
- Return mean $\bar{x}$, variance $M_2 / (n - 1)$.
Vector case is similar.