Throughout my life, I’ve learned from the experiences of those around me to broaden my understanding of the world and to help develop empathy.
As a white and mostly able-bodied person who has long understood themselves to be cis, male, and straight, working to understand the lived experiences of people of color, those with disabilities, and LGBTQIA+ people has helped me to understand how my own privilege has shaped my own experiences.
That understanding has in turn helped me to be a better ally for those around me.
The work to understand the lived experiences of those around me has had another effect, however, that I’d like to take a few moments to explore today.
In particular, I’ve been working to understand myself and my own gender lately in ways that I haven’t thought to understand before.
Just as the openness with which my friends and my peers has helped me in doing so, I’d like to be open with my own questions and understanding to help others in turn.
Taking a few steps back, then, one thing that quarantine and social distancing has made very clear to me over the past few months is the subtle pressure that I have felt throughout my life to perform my gender in a particular way, and within particular constraints.
Distancing from society except through remote channels where I appear as a really neat icon (thank you again, @DataErase!), I haven’t felt that same pressure, and have come to understand that pressure better in its absence.
For as long as I remember, I’ve been confident enough in my masculinity to break with convention by having long hair, getting every random object that I can to be pink, carrying a purse when it suits me, and so forth.
Absent that pressure to conform, though, has left me asking another question entirely about myself: am I confident enough to not be masculine at all.
At one point, I found myself looking in the mirror and asking myself how I even knew that I was cis and male, and for the first time in my life, not having an answer.
In the past two months since that moment, I’ve reexamined a lot of my life up until now, connecting dots between memories and re-interpreting my experiences without forcing those experiences into a cisgender-shaped box.
That process of questioning myself and my gender has been on one hand liberating and self-actualizing, and also quite scary — what will happen if someone sees me in a dress or a skirt as I explore different ways to present myself, or how do I allow myself to explore my gender when I look in the mirror only to get stuck on seeing my facial hair?
What comments will people make when I turn on my camera in meetings if I decide to change my appearance even a little bit to try and explore how my appearance and gender relate to each other?
How will toxic individuals — the same people who delight in misgendering my peers — respond to my exploration?
What does it mean for me to be an LGBTQIA+ ally, especially during Pride month!, if I can’t even say definitively what my own gender is?
The cognitive dissonance as I unambiguously declare that I’m a cis white man so as to be honest about my own privilege has made otherwise ordinary discussions feel all the more surreal.
In my uncertainty about my own self, any label feels like a costume that doesn’t quite fit right; that itches when I think too hard about it.
I can feel like an imposter if I present as anything other than cis and male, or that I’m in denial if I define myself only in terms of my previous certainty.
To be sure, I don’t mean to claim that I am non-binary, that I am trans, or that I am cis; only that I’m working to understand myself in ways I never allowed myself to before, and that society at large continues to discourage.
I have no idea where that will land, but in the meantime, I’m exceptionally grateful for the support of the people around me.
It has been amazingly helpful to talk to my wife, Sarah Kaiser, and to have her along my journey, just as I was there for her journey towards coming out as bisexual.
Knowing that my parents and brother are there and love me no matter where this journey goes has helped to create a safe space in which I can understand myself.
Support, advice, and understanding from peers and colleagues has helped me to find a community in which I can express myself whomever I can.
I’m grateful as well for the many trans and/or non-binary people who have made shared their experiences with gender; these examples have helped me feel like I’m not alone as I work to understand myself.
I also have to acknowledge the privilege inherent in the fact that I have access to inclusive therapy.
Asking questions and working to understand myself is the start of something, not the end, and I’m thankful for the community around me as I start that work.
Please disregard this post; it is only intended to check that GitHub Actions work correctly with jekyll-katex.
By way of context, it helps to revisit a little bit of what a quantum state is in the first place. Typically, if we have an n-qubit register, we think of a state ∣ψ⟩ of that register as being a vector with 2n complex elements; one for each possible classical bit string on n bits.
For example, when we write out a state in Dirac notation like ∣00⟩, we could have also written that same state out as a vector on four elements:
∣00⟩=⎝⎜⎜⎜⎛1000⎠⎟⎟⎟⎞.
As our system gets larger and larger, this gets more and more unwieldy. Even at three qubits, things get big in a hurry:
If you’re reading this, you’ve probably also read about some of the neat things you can do with Q# and quantum computing, and are eager to try out this whole quantum development thing. Like any other part of computing and development, there’s some skills that can really help you out on your way, so in this post I’ll talk about what some of those skills are and how you can practice the non-quantum stuff that will make your quantum journey a bit easier.
Before that, though, it’s worth mentioning a small bit of a disclaimer. There’s no one right skillset that you need for quantum computing. In my previous post, I talked a bit about my path towards quantum computing, and about how rewarding it can be to work with people that come at things from a different perspective and background. As you go forward with quantum computing, you’ll find your own way to make a difference, your own way to leave both the technology and the community better than how you found it. Thus, my focus here isn’t on what skills you need, but what skills can be useful. You don’t need to be an expert in everything or even any one thing in particular in order to get going with quantum computing.
With that caveat in mind, then, let’s get down to brass tacks and explore some things you may find helpful along your way.
Math
Even though it’s not required, being comfortable with math can be really quite helpful as a quantum developer. Most documentation in quantum programming languages involves at least a bit of math, so being familiar with a few mathematical concepts can help you make the most out of the resources that are already out there. The most fundamental descriptions of quantum computing are expressed using ideas from linear algebra and complex numbers, such that a familiarity with each can help you peel back the layers a bit and see how things work.
That doesn’t mean you’re doing quantum computing on hard mode if you aren’t a PhD-level mathematician, though. Really, this is another way that quantum computing is a lot like other areas of computing. If you try to read about OpenGL, knowing some math will help you get the most out of documentation. Similarly, machine learning involves a fair bit of math, you can also get quite a ways by following along with examples or using high-level libraries.
What’s really exciting, though, is that you can also practice your math skills as you go. In our Q# book, Sarah Kaiser and I write most of our the QuTiP package for Python to handle doing most of the math, so that you can jump right in and see how things work without having to do all of the math yourself.
If you want to preload things a bit, though, refreshing your memory on linear algebra and complex numbers will give you a head start with quantum computing content.
Classical Software Development
As I talked about in my previous post, many of the skills that help me out the most as a quantum developer are classical software development skills. Brushing up on classical languages like Python or C#, unit testing, how to manage projects with Git, how to work with containers, how to write and test code with an IDE, or any number of other skills can help you contribute to open source quantum projects, and can help you to make progress with your own projects.
Thankfully, there’s a lot of good resources to help you out here, dev.to itself not the least of them! If you’re already a seasoned software developer, that will help you out as you go forward with quantum computing. On the other hand, if you’re new to software development, welcome! Your original way of looking at and learning about computing will help you make a difference with quantum computing.
Writing
There’s no way to underestimate this one. Quantum computing is a big field, bringing together a lot of different ideas and ways of looking at the world. That means that as you progress through your quantum computing journey, you’ll write e-mails, tweets, blog posts, documentation, and many other kinds of things in order to communicate those ideas with your community.
That’s not to say you need to be an amazing novelist, of course (though if you are, awesome! 💖). Rather, my point is that math and prose go hand-in-hand for communicating quantum ideas. Being comfortable with writing isn’t necessary to get started in quantum computing, but it can help you ask questions on StackOverflow that help others on their journey, to file informative and descriptive bug reports, to improve Wikipedia articles that others use to look up quantum concepts, and can help you explain ways of looking at quantum computing that you found useful. As you build your own quantum projects, your writing skills can help you make documentation that lowers barriers instead of raising them.
In my experience, there’s two main parts to getting better at writing. The first? Reading. Spend time on dev.to, Twitter, StackExchange, arXiv, and whatever other platforms you find useful for talking about quantum computing. Pay attention to what things other writers do that help you, and what things make it harder for you to learn, so that you can use that in your own writing. The other part of brushing up on writing skills, of course, is to practice. Even if you think it’s crappy, writing a lot can help you find a voice that you can use to make the quantum computing community that much more wonderful.
Empathy
The last and absolute most important skill that I can suggest practicing is empathy; it may even be the only mandatory skill on this list. Quantum computing, just like every other kind of computing, is a thing that humans do. Listening to those humans — your peers! — can help you understand where they get stuck and might need a little help, where they need your help making the community the best it can be, and where they might be able to help you get unstuck.
Your peers in the quantum community come from all walks of life, not just in terms of skills, but also in terms of who they are as people. The quantum computing community includes people of all genders, sexualities, races, nationalities, and kinds of disabilities. Listening to your peers can help you break down the barriers that they face in any number of small and large ways. By putting empathy into practice, you can ensure that you not only make a difference in the quantum community, but that you make a difference for the better.
Quantum computing has been, to put it mildly, in the news a bit as of late.
With so many different announcements about and developments in quantum computing, it can feel a bit daunting to jump in and get started.
Sometimes, quantum computing can even pick up an air of mystique about it, given popular analogies such as “two places at once,” “action at a distance,” and other pretty confusing explanations.
While there’s thankfully quite a range of good content out there to help you get started, it can still be hard to get a feeling for what it’s like to actually be a quantum developer.
As I talk to people at the bar, in carpools, on Twitter, at conferences, and the like, saying that I work on quantum computing can be a bit of a conversation killer; sure quantum computing is cool, but what do I do?
With this post, I’d like help to demystify things a little bit by talking about what quantum development is like for me as I go about my day.
WHOAMI?
But first because everyone’s path to quantum development looks different, a little bit about myself can provide some helpful context.
I’m Cassandra Granade, a research software development engineer in the Quantum System group at Microsoft.
Before that, I did a triple-major at the University of Alaska Fairbanks, a Masters degree at the Perimeter Institute, a PhD at the Institute for Quantum Computing, and a postdoc at the University of Sydney.
Needless to say, learning about quantum computing has been a bit of a thing for me throughout much of my life.
In my spare time, I’m as liable to be shitposting surreal memes, planning a World of Darkness tabletop campaign, or taking our adorable puppy for a walk to one of Seattle’s surprisingly numerous dog-friendly breweries.
insert pun here
Given that, one might think I spend all day buried in obscure journal papers, nose-deep in a pen-and-paper calculation, or scrawling at a chalkboard.
While those are all completely valid and useful ways of working on quantum computing, I’ve tried my hand at them and found that at least for myself, there are other ways I can contribute.
Even before starting in undergrad, for example, I have always found a joy in solving problems using programming.
I got my start back with QBASIC and GWBASIC (yes, I am officially an Old; I’m also a Millennial, somehow?), and loved that I could use programming to get answers to things I was curious about.
When I wanted to understand population growth and how that affected ecology better, I borrowed my mom’s population dynamics textbook and started programming things up as VBA macros in Excel.
As it turns out, that’s a great approach to working with quantum computing as well.
Building a quantum computer is hard, and there’s lots of ways that classical computers help us out on our way there.
We can use classical computers to model what we want quantum computers to do, using linear algebra packages to help us out, or we can use classical computers to run statistical inference algorithms on the data we get back from quantum devices to help us understand how to make better ones.
Of course, we can go much further as well and use classical computers to write and test the actual programs we want to run on quantum computers; hence the emergence of quantum programming languages like Q#!
So, what do you do?
As soon as you start using classical computers to solve problems of any sort, you get back into the fun issues of building, testing, packaging, deploying, and designing classical software.
Recently, as a part of the 2019 Q# Advent Calendar, Andres Paz explained many of the pieces that make up Q# and the Quantum Development Kit.
Making Q# work involves writing classical compilers and simulators, integrating with existing languages like C# and Python, making editor integration extensions to help us write quantum programs in the first place, writing documentation for everything, and even making Docker containers to power online-first experiences for Q#.
This is a team effort, as designing, building, and maintaining the Quantum Development Kit necessarily involves more kinds of expertise what any one member of the team brings with them.
For myself, I tend to fit into that team effort by designing and maintaining the different Q# libraries that come with the QDK, and by working with domain experts to make those libraries as awesome as they can be.
This means that a large part of my day is writing unit tests in Q#, fixing things when builds fail, reading through pull requests, and working on the best way to package things up so that other quantum developers can make use of the code that I help out with.
If you’re curious to see more of what I do, follow me on GitHub!
Since the Quantum Development Kit is open source, you can follow along as we add new features, fix bugs, introduce new bugs, and otherwise do what you’d expect software developers to do.
Put differently, a large part of the skills that help me as a quantum developer are the same skills that help out in any other software development engineering role.
While I do use the skills that I’ve learned throughout my quantum computing training on a daily basis, it’s the traditional software development engineering practices that give me the basis I need to make use of those skills.
There’s a point to all this, right?
As you get involved in quantum computing, you’ll bring your own skills, background, and experience to what you do.
There’s no one way to be a quantum developer, or to contribute to the quantum computing community.
My hope is that by showing my particular path, I can provide an example of the way I use my particular background to help the community.
Your path will look different, and that’s not just OK but wonderful.
The breath of different skills and backgrounds that come to bear on quantum computing is one of the most amazing things about this field.
You’ll do amazing things here, and you’ll do them your way.
This post is part of the Q# Advent Calendar 2019. Follow the calendar for other great posts!
Introduction
Almost three years ago, I wrote here about the importance of reproducible research, and about tools that can be used to make it easier to perform research in a way that makes reproduciblity easy.
Making it easy to do research in a reproducible fashion is critical — not just to avoid the gatekeeping that all too often comes along with research, but also because people are much more likely to do the things that we encourage them to do.
Though reproducible research is critical throughout science, it’s also near and dear to my own heart given the importance to quantum computing.
Looking back at my post, a lot can change in three years.
That’s definitely been true in the quantum computing community.
Indeed, three years ago, the quantum computing community was much smaller, and much more heavily focused on more abstract research results.
As the community has grown, we’ve seen a huge growth in both the number and variety of tools available to help explore quantum computing through reproducible research.
In this post, I’ll take an opportunity to highlight how it’s easier than ever to get started in reproducible quantum computing research.
Let’s start with the punchline, though: the only software you need to get started is a browser.
If you don’t already have an Azure subscription, you can get $200 worth of free credits to help you get started.
Note that if you’re at a university or other research instutition, they may also have purchased an Azure subscription already.
In either case, I’ve put together a template to help you get started, so let’s go on and get started.
Go to https://github.com/cgranade/quantum-research-template, and you should see a button labeled “Use this template.”
When you click that button, you’ll be prompted to make your own GitHub repository to help collect your work and share it with your collaborators.
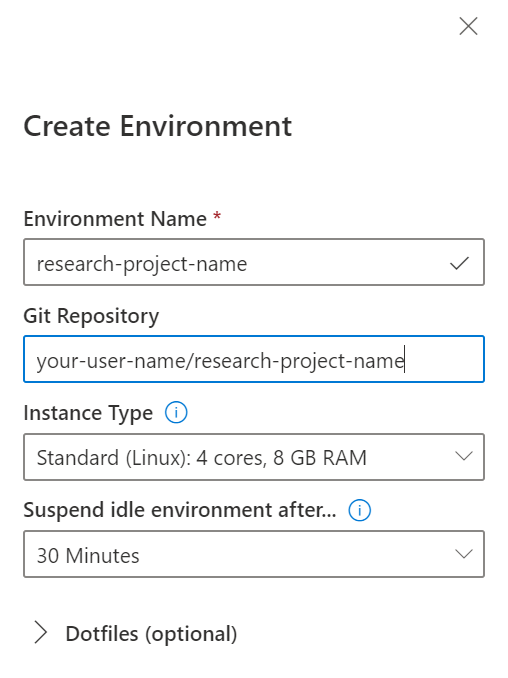
Go on and give your new repository a name, and press “Create repository from template.”
It will take a few moments, but then you’ll have a repo all setup with the start of a LaTeX manuscript, some Q# code, and a script that will package everything up for uploading to the arXiv.
Next, let’s go to Visual Studio Online and use your new repository to setup an environment.
The template you copied in the previous step comes with instructions that Visual Studio Online can use to install LaTeX, Python, the .NET Core SDK, and other software that’s helpful for doing quantum research.
Go to http://online.visualstudio.com/ and click “Get Started.”
Sign in with the account you use to get to your Azure subscription, and you’ll be taken to the main Visual Studio Online portal.
Note that you may be prompted to create a plan if you haven’t already done so.
This tells Visual Studio Online what subscription you want to use with your new environment; handy if you have multiple subscriptions.
In any case, press “Create environment,” give your new environment a name and then put in the name of the repo you created above.
Once you do all that, time to grab a coffee (or, if you’re Chris Ferrie, a couple coffees).
By the time you get back, your new environment should be up and running, with everything installed from the template.
You can then write Q# code, run it, and embed the code directly into your paper.
Go on and try it out!
Open up src/Operations.qs from the side bar, and replace the definition of HelloQ with the following Q# code:
open Microsoft.Quantum.Measurement;
operation HelloQ() : Unit {
let randomBit = SampleRandomBit();
Message($"Got {randomBit}!");
}
operation SampleRandomBit() : Result {
using (q = Qubit()) {
return MResetX(q);
}
}
Next, open up your TeX manuscript, and try changing some text.
Whenever you save, your manuscript will automatically recompile and import the changes you made to your Q# sources.
Of course, you can run things too.
Press Ctrl+` or Command+` to bring up a terminal window, then run the following commands to see what your new Q# program does:
$ cd src
$ dotnet run
Got One!
If you prefer Python, that’s cool too:
$ python host.py
Got 0!
When you’re ready to post to the arXiv, that’s just as straightforward:
$ cd ..
$ pwsh Export-ArXiv.ps1
Taking a step back, you got started writing quantum programs in Q#, included them in your manuscript, and got them ready for publication, all without installing a single piece of software.
Where this really helps with reproducibility, though, is that your collaborators can also make a Visual Studio Online environment from your new repository.
That will ensure that they run exactly the same software that you use for your part of the project.
When you’re done, you can go on and upload to arXiv using the provided script, making sure that all your source code comes along with your result.
There’s a Lot to Unpack Here
If the above all seems like magic, it isn’t: it’s the power of using the best open-source platforms around to do research.
Let’s see how that all comes together by taking a trip through the various technologies that you used in your template above.
Contain Yourself
The first thing to look at is the concept of a container.
Using Q# to do reproducible research, your software stack might look a little different than it did three years ago.
For example, if you want to use Q# together with great host languages like C# or Python, and then include all of that into a paper written with LaTeX, you may wind up needing a variety of different tools:
.NET Core SDK (used to provide the Q# compiler)
Python
TeX / LaTeX
Jupyter Notebook
Visual Studio Code
Git
While thankfully these tools are all pretty straightforward to install, for reproducible research, that can present a bit of a challenge.
The more dependencies you take, the greater the chance one of your collaborators, referees, or readers will have a different version of something than what you used.
That can make it difficult to run your code and to verify your results.
This is also a problem for very different reasons in many other areas of computing, so for research purposes, we can borrow a trick or two to help us out.
In particular, the past few years have seen an explosion in the use of containers to isolate application dependencies for each other, and to deploy software in a robust way.
We can use that same idea to help out with research!
Much like Python’s virtual environments or Anaconda’s conda envs, containers can be used to manage side-by-side software installations, letting you use different versions of software packages for different projects.
The Quantum Development Kit uses this concept, for instance, to package everything you need to use IQ# in Jupyter Notebooks into a single container.
The instructions on the IQ# repository tell Docker, a popular container engine, how to build that container by installing different other packages into the IQ# container.
Once you have a container like one built to use IQ# and the Quantum Development Kit, there’s any number of different ways you can use it to do awesome stuff.
If you’ve used the zero-install version of the quantum katas, for instance, that uses the IQ# container together with a really neat open-source service called Binder.
When you use Binder with a project, that launches a new VM for you, builds a new container from the IQ# container, and forwards the Jupyter Notebook server running in the new container over to you.
While that is fairly complicated, it means a really straightforward experience for you when you try out different research, tutorials, or other content hosted on Binder.
Getting a Bit More Remote
It turns out that Visual Studio Code can make use of the same kinds of container technology to help you develop your research.
If you noticed, there’s a folder called .devcontainer in the Quantum Development Kit samples, the quantum katas, the Q# libraries, and even in the template you just used above.
These folders specify what containers to use when developing on those projects.
Once you have the right extension installed, when you open one of those repositories, that builds a new container from the instructions in .devcontainer.
Most of Visual Studio Code then runs inside that new container; only the graphical interface is running on your normal operating system.
From the standpoint of reproducibility, that’s great, as it means that all the software you use for a project is specified in one place, irrespective of what you might have installed on your normal OS.
Because the Quantum Development Kit is provided as a container, it’s really easy to use with devcontainers as well.
Very Online
What does all this have to do with Visual Studio Online, though?
It all comes down to that Visual Studio Code is built on another popular open-source technology, called Electron.
Electron works by embedding a version of Chrome to run your different apps.
This means that Visual Studio Code is effectively a web app tied to a special-purpose copy of Chrome.
You can even press Ctrl+Shift+I or Command+Shift+I to get to the same debugger tools as
Most of Visual Studio Code is written using web platforms like HTML, CSS, and TypeScript, similar to how you might make a traditional web app.
This means that the browser-based version of Visual Studio Online can work very similarly to Visual Studio Code, reusing existing technologies.
Phew, What Now?
Research is best when we share it with people, collaborate on new ideas, and expand the communities around us.
Reproducible research helps us realize on those goals by making sure that our results are trustworthy and can form the basis for new research, new ideas, and new communitity members.
When we apply this insight to a quickly growing field like quantum computing, that only becomes more urgent.
It’s all too easy to put up new walls, jealously guard our research, and close ourselves in.
Thankfully, services like Visual Studio Online and open-source platforms like the Quantum Development Kit can use help us make the most of our research and be the best members of the quantum computing community that we can be.
In this post, I tried to give a small taste of that, but it definitely doesn’t stop here.
Please explore, try things out, and leave the quantum computing research community a better place than you found it! 💕